









In the Parts I and II of this series we have addressed the key ideas underpinning the notion of on-chain reputation. We have elaborated on why, given the nascency of these concepts, we need a new vocabulary to even agree that we are talking about the same subject matter. Likewise, upon defining the vocabulary and agreeing on the terms, we have laid down the desired conceptual properties of on-chain reputation functions.
Our core message is that on-chain reputation is the ultimate use-case for the web3 identity stack, but only so if the desired properties are achieved.
The second part of this series delved deeper into the mathematical properties of optimal reputation functions. We have derived a basic model for game theoretically coherent behavior of effort/reward optimizing agents. We have then shown that there exists such an expressive functional form that enables all core use-cases for persistent reputation.
We are now proceeding to arguably the most challenging part of our exploration - that of defining which technological stack is most optimal for achieving all the properties - mathematical and conceptual - that we have addressed in this series. Cryptographic properties as well as computational feasibility would be the focus of this part.
Brace yourselves for quite a ride, dear reader, as the following text will bring you deep down the rabbit hole of some of the most exotic cryptographic primitives - those that will change the surface and the depth of the internet as we know it.
Let's get started.
The Setup
Implementing a reputation system that is both private and supports penalties for unwanted behavior (called reputation slashing) is a stiff challenge.
Privacy is essential for Galactica because it deals with encrypted personal data on a public blockchain with publicly viewable transactions. Thus, the design should eliminate any even purely theoretical attack vectors around the system privacy stack.
Reputation slashing is desirable because it can penalize unwanted behavior and enable use cases, such as undercollateralized lending.
As one shall see below, the major unexplored area in designing a holistic web3 reputation system lies in combining privacy and verifiability. When solved for, these two properties combined can enable use-cases that everyone has been speaking of since the very emergence of blockchains as subjects of public discourse, but yet none of which have emerged to-date as production ready systems. To be precise, Galactica is not the first project to attempt to tackle issues such as enabling undercollateralized lending, holistic identity stack or functional on-chain reputation. All these concepts are known, well explored and evidently valuable. But why have none of them really emerged to-date?
Let us offer you a very simple explanation.
Zero-knowledge cryptography (ZKC) and Fully Homomorphic Encryption (FHE) offer great solutions for privacy. They allow proving statements and processing data without disclosing underlying confidential information. But in a practical setup, both of these sets of cryptographic primitives still leak data and these leaks can accumulate over time, thus preventing us from achieving the desired level of privacy. Even if the personal data stays confidential, an outside observer can track the transactions an account has made over time. Selective disclosures through ZK and the contracts an account is frequently interacting with shows which requirements the person owning the account fulfills. In the case of sufficiently diverse requirements fulfilled, many properties of a user's private profile can reliably be inferred by a reasonably equipped outside observer. For example, an account uses a lending platform for Canadian residents only, participates in a DAO for individuals under 20 years, holds a particular NFT, and has sent tokens to an account selling tickets for a specific conference.
All these interactions expose little bits and pieces of a Persistent Identity that can easily be combined to 'reverse engineer' the seemingly encrypted digital footprint of a real person behind it.
A promising solution for preventing this kind of unwanted inference is to split on-chain activity over multiple accounts. This ensures that on-chain disclosures and activity do not accumulate into an identifiable profile. However it requires caution on the side of the user - not to link accounts accidentally, e.g., by sending funds between accounts without mixers. These can be easily ameliorated with modern open source libraries and the most basic OpSec practices.
For reputation slashing and the use cases enabled by it, multiple private accounts are a challenge as the data from all accounts may be relevant. Reputation slashing here is a game-theoretical rather than mathematical concept - it would include any use-case where a user has an incentive to conceal a part of one's Web3 Footprint, such as non-compliance or adverse credit history. For example, to solve for regulatory compliance, a reputation function such as 'KYCed user never sent tokens to a sanctioned address' only works if it is enforced to include all accounts. This can be done by maintaining a list of all accounts that share the personal KYC data, identified by the humanID hash, a unique identifier derived from personal data such as name, birthday and nationality. The list needs to consist of encrypted addresses or commitments that the user has to fill out in a ZK proof.
However, there are a few challenges in relation to this approach, when trying to achieve all desired reputation properties.
The Challenges
Combining Reputation Scores Across Accounts
When the user has multiple accounts and the system provides a reputation score for each account, the system should be able to combine those scores into an overall reputation for the owner. Depending on which mathematical primitives the reputation function is using, this might be complicated.
For some reputation functions, it is simple to combine reputation scores of accounts into a total score. One simple example is the reputation function counting transactions to a particular smart contract. The sum of the transaction counts of each account of a user would be the total reputation score. It is always the same, regardless of how the user distributes his activity.
Other reputation functions can not be combined that simply, for example a reputation function for the average swap volume. The same activity can be arranged differently over multiple accounts yielding different reputation results when trying to combine it in a trivial way.
Those more complex reputation functions cannot be combined over multiple accounts consistently. They are more challenging to implement. They require careful consideration to avoid unintended incentives. An approach to solve this is making more of the source data available for the algorithm combining reputation scores across accounts. For the example of the average swap volume, it would be enough to provide the number of transactions and sum of the transaction value, so that both can be combined separately before taking the average. Depending on the complexity of the reputation function, it can be difficult to provide enough source data without reaching the limits of data availability, privacy or computational effort.
Private Reputation Proof Generation
When a user splits the on-chain activity over multiple accounts for privacy reasons, it is desirable to keep the list of accounts that belong to the same user confidential. The reputation system should be able to calculate a total reputation score for a user by combining reputation scores of all accounts. A ZK proof can do this without revealing the list of accounts owned by the user. It can verify inputs, the reputation scores for accounts, with aMerkle proof. This way, only the Merkle root is disclosed and not the account's address. Then the proof can combine multiple Merkle proofs to query the reputation score for each of the user's accounts and combine it into an overall reputation score for the user.
This approach works well in theory, however has significant limitations in practice.
The tree data, representing a mapping from account to reputation score, needs to be available to generate proofs.
The generation of the ZK proof is computationally heavy and increases with the amount of data that is processed and the complexity of the ZK circuit. One of the disadvantages of ZKC is that circuits have a fixed size. This means that, if a circuit has the capacity to combine reputation from 4 accounts, all generated proofs take similar computation effort, no matter if the user has 1, 2, 3 or 4 private accounts.
To keep personal data private, Galactica relies on self custody by users. They store zkCertificates data and keys on their own device(s) and generate ZK proofs locally. Therefore, the reputation proof computation should work on consumer-level hardware with an acceptable user experience regarding simplicity and responsiveness.
Benchmarks with early prototypes for reputation proofs showed that existing solutions are far from feasible. We attempted both - storing reputation in Merkle trees and using Patricia trees, an efficient specialization of Merkle trees for key-value mappings as used by Ethereum.
Patricia treesare suitable for representing the address to reputation score mapping. But the fixed size property of ZK circuits and the path encoding overhead result in very large circuits. A prototype simplified from an existing Patricia tree circuit has a size of about 100k non-linear constraints for a single account. The prover binary is about 0.4 GB large and 64 GB of RAM is insufficient to compile it.
Merkle tree proofsare more manageable with about 7k non-linear constraints per proof if the tree holds 2^32 entries. However, because they do not support a clear address mapping, entries need to be updated in a UTXO-based model. This leads to minutes wait times (depending on the amount of logs and the speed of the endpoint) on the user side when querying and processing blockchain logs to find the user's latest UTXO entries. A specialized indexing service could assist users in this step. By building a database of previous UTXOs, it can preprocess the data and serve user queries much faster. However this comes with a privacy cost of disclosing to an external party what accounts are searched for. When a user queries UTXOs for a specific account, the indexer providing the service can track it in association with the user's IP and track that account and IP. This means the indexing server provider could collect information on a user based on IP tracking and correlating query timings.
There are two promising alternatives for solving the problem of storing and combining reputation privately:
Fully homomorphic encryption is a form of encryption that allows general computation on encrypted data without having to decrypt the data first.
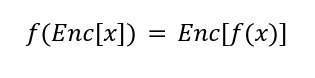
Zama.ai integrates this advanced type of encryption into an EVM extension called fhEVM. It enables smart contracts to process encrypted data confidentially and to programmatically define rules for sharing and decrypting the data. This system provides an approach for compliant privacy that is different from Galactica's approach utilizing ZKC. fhEVM allows the computation to take place on the public blockchain, whereas with ZKC the computation takes place on the prover's side and the blockchain only verifies that the result is valid using the ZKP. This means that fhEVM requires far less computational effort on the user side and that ZKC is more efficient to verify. An advantage of ZKC compared to FHE is that it offers more existing implementations for blockchain use-cases such as Merkle trees.
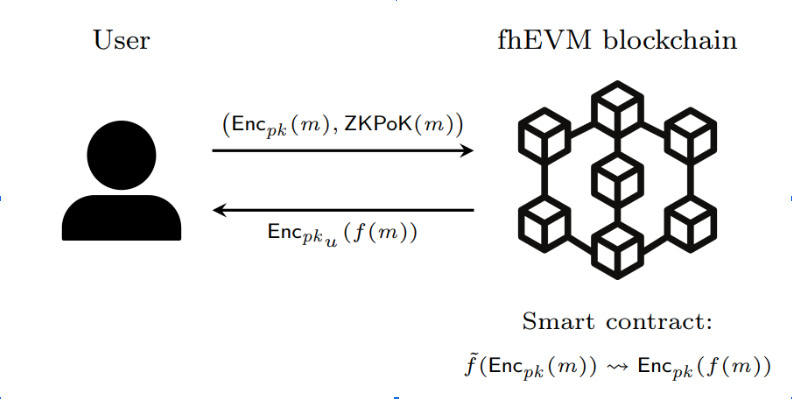
Figure 1: The user can send personal data in an encrypted form to the fhEVM blockchain accompanied with a ZK proof of knowing the content. It is processed confidentially according to logic defined in smart contracts. To output data, a read transaction must pass smart contract checks before the validators reencrypt it with the user's key using Multi Party Computation. [fhEVM whitepaper]
Combining the ZKC and fhEVM unlocks many new capabilities for Galactica. The combination can make the usage of compliant privacy simpler by moving computation effort to thevalidators. Specifically for private reputation proofs, it would require the user to only generate small ZK proofs for the reputation score of each account. The combination into an overall reputation score for the user can be done in an encrypted form in the smart contract. This is not possible without fhEVM, as disclosing the reputation score of a single account can compromise privacy. A third party would be able to recompute reputation scores for all accounts to check which ones have the same reputation score as the disclosed one. Hurdles for the integration of fhEVM into Galactica are: (a) the unknown impact on Galactica validator performance, and (b) that fhEVM is not production-ready for MainNet.
Verkle trees are an advanced alternative (utilized by Ethereum*) to Merkle trees serving the same function - to represent large amounts of data in a single root and allow efficient proofs for inclusion of specific data points. The difference is that Verkle trees use vector commitments to achieve smaller proofs and to combine multiple data points into one proof. These properties are ideal for efficiently and verifiably querying reputation scores for multiple accounts in a ZKP so that they can be combined into an overall score on low spec hardware.
The disadvantage is that Verkle trees are a rather new technology that has less mature implementations and requires more effort for integration in the Galactica technology stack.
There is a benefit in combining both approaches because Verkle trees alone do not solve all issues of reputation proofs. Verkle trees are probably so much more efficient, that reputation proofs are manageable even for many accounts in a single step. However they still leave all the compute gathering required data on the user's side, leading to usability problems.
FHE solves this part efficiently as all the 'hard work' is done by professional validators and users only need to do a simple task. Also voluntary disclosure is more elegant on FHE as it can be defined in smart contract logic instead of sending shamir shards to a list of fraud investigation institutions.
Reputation Storage Model
Because reputation functions are user-defined and based on the whole web3 footprint, there are challenges in data availability, storage, and computation.
For example, if a user defines a reputation function counting previous transactions of an account, the calculation requires accessing and processing all past transactions. To query reputation scores efficiently, the source data is aggregated into metrics, such as the transaction count, that can be continuously updated with low effort. As the initial computation of a newly defined metric has to process the existing transaction history, it might be too heavy to fit into the update time of a single block and therefore requires an asynchronous initialization of reputation metrics. This brings challenges for the blockchain consensus because some validators might take longer to process the data.
The storage of those metrics for each relevant account as well as the initial setup and continuous update lead to hardware and compute cost. The economic model to pay for these costs of reputation in the Galactica protocol is an open question.
A potential approach to simplify storage and compute requirements is limiting the reputation functions to a set of predetermined metrics and operations. This would allow precomputing and sharing metrics for all reputation functions so that no costly initialization process is required for new reputation functions. Naturally, this would limit the expressiveness of reputation functions.
Another question ishow to store reputation scoresso that they are accessible to smart contracts, while supporting privacy. Merkle trees and their variants (Patricia trees and Verkle trees) are a promising choice because they support private data lookups through ZK Merkle proofs. However, generating those proofs requires access to the data in the Merkle tree and computational effort for the ZK proof. This can impact the user experience as both downloading Merkle tree data and generating the proof may take significant time (minutes).
An alternative would be a mapping from account addresses and reputation function to a reputation score. This is faster to process, but not able to conceal for which accounts the reputation was used.
Storing reputation scores on-chain in an encrypted way using FHE is an interesting option too. It would be great for privately using reputation, so that others do not know the value. It can also be computed and processed without requiring effort on the user side, but reading and evaluating require user approval. However it would be computationally costly to keep reputation data in encrypted form updated because FHE operations are expensive and transactions impacting reputation are expected to be frequent. Furthermore it is hard to confidentially combine reputation across accounts in FHE because the traces of accounts and transactions impacting encrypted reputation values would be public.
Due to those disadvantages, Galactica focuses on calculating and storing reputation outside of FHE. Many of FHE's advantages are still available because it is possible to encrypt reputation data for onboarding in FHE whenever needed.
Real-Time Reputation
Time-consuming generation of reputation proofs is also a problem for ensuring up-to-date information. A possible attack vector on reputation are flash attacks bundling malicious behavior, so that subsequent actions might be based on outdated reputation information. This problem is only relevant for functions supporting reputation slashing because monotonically increasing reputation functions do not decrease.
To solve this challenge, reputation either needs to be updated during the transaction processing, which is infeasible for privacy through ZK Merkle proofs, or each transaction needs to record reputation requirements so that the postprocessing of a transaction in the validator can check if the requirements still hold after all actions performed in the transaction.
Where to Calculate Reputation Scores?
Since calculating reputation functions for an account involves processing lots of data from the transaction history, it is infeasible to pack the computation into a ZK proof.
As reputation should be verifiable and permissionless, it would make sense to calculate reputation directly as part of the blockchain protocol or alternatively use off-chain oracles that make reputation values available on-chain. Integrating it into the protocol as part of the validator node simplifies the data availability, however puts computational load on the validator and the additional complexity is a risk for the stability of the network.
The solution through oracles is more modular and simple, but requires a trusted operator. An option to reduce the required trust is to depend on a network of reputation nodes instead. They could specialize on reputation calculation to be more efficient than a direct integration in the Galactica node, while still providing more decentralization than a single oracle. However, providing real-time reputation would only be feasible with direct node integration to process transactions without significant delays.
Puzzle-Pieces for the Technical Design
Reputation on Private Data
Galactica handles personal data, such as KYC, that is verifiable on-chain through confidential zkCertificates and ZK proofs. It would be nice to utilize this data in reputation functions. For example it would be useful to have a reputation function that considers if a person's name is on a sanction list. However this personal data cannot be used directly for reputation because the raw data is not available to third parties calculating or verifying reputation.
There are two ways to solve this challenge:
Intermediate Disclosures:To provide data for a reputation function, a user can publish a selective disclosure on-chain. For example, this can be a ZK proof about not being on a sanction list. After submitting this proof in a transaction and verification on-chain, an SBT is issued for the sending address. This SBT can be used for calculating the reputation.
Fully homomorphic encryption: Using FHE, personal data can be stored in encrypted form on-chain. It can be processed in a confidential manner by anyone trying to calculate the reputation of an address. The result would be an encrypted reputation score that can be used in further FHE operations, such as receiving an encrypted amount of tokens for an airdrop (example implementation of encrypted tokens by Zama). Compared to intermediate disclosures with ZK proofs, this approach works without requiring the user's interaction. Depending on the implementation, the user only has to approve providing the encrypted data to the reputation calculation beforehand. The disadvantage of this approach is that the calculation takes significantly longer to compute and that the set of available operations is limited and not turing complete.
How to Divide On-chain Activity?
To prevent selective disclosures from accumulating into a trackable profile of a user, activity on-chain can be split to different accounts. For example, a user might use one account for long term investments on an account secured by a hardware wallet, another account for regular governance duties on a hot wallet and a third account for meme coins and games.
The user can just generate or derive new accounts on his own as on any other EVM-compatible chains.
When activity is split for privacy reasons, there are a few challenges of operating this way without accidentally linking the accounts in the public transaction history. Funds should be moved through privacy mixing protocols and selective disclosures should not show that both accounts share the same humanID for a DApp.
Linking Accounts for Reputation
As discussed above, it is useful and we believe necessary for the reputation system to enable the combination of reputation data from multiple accounts, for example to prove that the user has never interacted with sanctioned addresses, regardless of the account used.
To solve this challenge, the reputation system needs a way to link a user's account without disclosing that link publicly. This can be done using ZK circuits and a list of encrypted addresses of the user. Doing everything in a ZK proof would be too expensive computationally to run it on the user's machine in self custody. Therefore it makes sense to limit the ZK proof to the minimum by only providing intermediate reputation scores for accounts. The rest is pushed to other computation layers, the reputation calculation in the node and the FHE smart contract system for combining account scores into a total user score. This way a lot of the heavy computation work can be outsourced to professional validators, so that the remaining work is as user friendly as possible.
The ZK proof on the user side is still required because the node and FHE can not keep the confidentiality of which accounts belong to the user. If the minimal ZK proof is still too heavy for user hardware, Verkle trees can be a possibility to make them efficient enough.
Whenever a new account registers using a zkKYC, the ZK proof can add the account to the list of accounts associated with the humanID behind the KYC. This list can be used in ZK proofs combining the reputation of all addresses as long as the ZK proof can hide which accounts the reputation was queried for.
The limitation of this approach is that the reputation proof only covers accounts that have registered a zkKYC before.
Sharing zkKYC Between Accounts
A zkKYC can be shared between multiple accounts because Galactica's zkKYC system allows a KYC to authorize an account using a signature of the account holding the zkkYC. The ZK circuit ensures that the signature is valid and matches the holder of the zkKYC.
Technical Design Conclusion
As discussed above, a number of questions remain, about the technical design of Galactica's reputation system. The main challenges for achieving all desired reputation goals are:
Combining user privacy and protection against tracking, with support for reputation slashing requires to force inclusion of all accounts.
Finding solutions with sufficiently good user experience as many approaches increase the system complexity and thus cost the user more time to access data, generate proofs or, in the fhEVM case, impact validator performance in a way that decreases the blockchain throughput.
Finding a solution for protecting against reputation flash attacks, such as updating reputation in 'real-time' during transaction processing without overloading the validator nodes.
Storing reputation data in a way that is accessible, efficient, and private enough.
Finding feasible solutions to those challenges can involve adopting new technologies, such as fhEVM, making simplifications or reducing the requirements. For example removing the support for reputation slashing would simplify the reputation system significantly. Users would not need to be forced to include all accounts in reputation calculation and there would not be reputation flash attacks requiring real-time reputation. However those simplifications also limit the amount of use cases, such as undercollateralized lending. It is up to future discussions which requirements are essential for a successful reputation system and what trade-offs exist.
The early versions of Galactica's reputation system will focus on a subset of features forming its MVP. Based on the community and builders' feedback we will learn more about its performance and importance of the various components of the reputation system.
*Verkle trees are used to improve the efficiency and scalability of data storage and retrieval on the Ethereum blockchain. They provide a more efficient way to organize and access data, particularly for state data, which includes account balances, smart contract storage, and other information critical to the operation of decentralized applications (DApps) on the Ethereum network. By using Verkle trees, Ethereum aims to reduce storage costs and increase the speed of accessing this data, which is necessary for enhancing the overall performance and scalability of the platform.